要说什么语言能最直观表达计算机的执行情况,那么除了几乎不可读的机器语言,便是汇编了.
参考文献
汇编语言简述
计算机的执行过程
注:本段对于计算机执行过程的描述做了简化,实际过程可能远远复杂甚至完全不同
计算机主要由cpu,主存,IO设备组成,它们通过总线将设备连接起来.cpu内部有一个触发器原件, 通过时钟脉冲的作用,每隔一段时间触发一次.触发时,根据cpu当时寄存器的状态,进行组合电路运算(所谓的运算,其实是将各个寄存器状态作为输入,然后通过组合电路后的输出作用与寄存器,在下一次运算前保持稳定).如果把cpu比做一个迭代器对象,寄存器比作其属性,其中有一个成员函数为根据当前状态运算下一个状态.如下为一个java模拟的cpu的运行的概念代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46interface CPU{
void next();//cpu执行方法
int getFrequency();//每隔多少ms执行一次,时间频率的倒数
void intercept();//中断,由特定的条件触发
}
public class X86CPU implements CPU{
private final static int WIDTH = 16;
private final static int FREQUENCY = 1000;//每隔1000ms执行一次
private byte[] ax = new byte[WIDTH];//ax寄存器
private byte[] bx = new byte[WIDTH];//bx寄存器
public static X86CPU createInstance(){
return new X86CPU();//可以进行一些初始化操作
}
public void next(){
//假设不识别任何指令,只进行寄存器+1操作
for(int i=0;i<WIDTH;i++){
ax[i]++;
bx[i]++;
}
}
public void intercept(){
//中断操作,设置寄存器的值,使得下一节拍后时候按照中断的指令执行
}
public int getFrequency(){
return FREQUENCY;
}
public String toString(){
//打印各个寄存器的值
}
public static void main(String args[]){
//开机
final CPU x86 = X86CPU.createInstance();
final int frequency = x86.getFrequency();
boolean stop = false;
while(!stop){
x86.next();
System.out.println(x86);
try{
Thread.sleep(frequency)
}catch(InterruptedException e){
//异常处理
}
}
//关机操作
}
}
当然,真实的情况远不是这么轻描淡写就能描述的,即使如jvm虚拟机那样的模拟器,使用高级语言来模拟也远远比这复杂,但即便如此,如果能很好的把要表达的重点简要说明出来也就够了.我们看到,在时钟脉冲的影响下,cpu电路有一次一次的执行,当然为了电路的稳定表示,时钟间隔是不会无穷小的,而时间隔越小,如何能做得更小取决于cpu的工艺和架构,显然越小,单位时间内可执行的指令数量更多.因此,主频是形容cpu性能的重要参数之一.
接下来,我们看看每一节拍cpu干些什么事儿呢?在8086下cpu根据寄存器IP和CS,计算当前指令取得的地址,在这里,会出现编码的细节,比如指令有多长等,在这里不再扩展,我们只要知道,cpu能读到对应的指令即可.在这里,机器能够直接识别的指令,我们把他通过助记符的形式表达出来,就成为了汇编语言中的汇编指令.也就是说,汇编指令与机器指令是一一对应的,除此之外,汇编语言提供伪指令,来辅助汇编器生成机器码时候的一些操作,伪指令不会生成对应的机器指令,但是会产生对应操作的意义.
如下为一段汇编代码:1
2mov ax,0xFF
db 0x00,0xFF,0xFF
第一行为汇编指令,表示将0xFF传送到ax寄存器,第二行为伪指令,也就是生成的文件中,在上一行生成的二进制机器码之后,紧接着是0x00,0xFF,0xFF.而接下来的章节中,我会逐渐介绍各个汇编指令和伪指令
汇编语言的语法
汇编语言作为机器语言的助记符,因此没有统一的语法规范,比较常见的语法是Intel语法和AT&T语法,两类语法虽然不能但几乎都可以等效相互转换.因此选择其中一种语法学习即可.在GCC中可以内联AT&T的汇编语言,而作为入门,我还是推荐使用nasm这个使用Intel的汇编器
- 首先nasm是开源软件,且跨平台.写法较为直观.
- 汇编后的机器码更干净
开发环境的准备
- NASM 到其官网[http://www.nasm.us/] 下载,并配置环境变量即可
- 虽然vim和emacs两大毒瘤我都在使用,但我就不安利了,一个趁手的文本编辑器即可.如:SublimeText3 VisualStudioCode等
- 一个二进制文本阅读器,哈哈vim又万能的可用了.其他用户可使用hex fiend等工具进行查看
一个漫长的Hello World
对汇编语言的helloworld绝对比其他语言漫长,这也是应该的,毕竟都在看汇编了,必然是希望把更多细节层面的东西掌握住
简单的入手
先试试看随意打印下代码1
2
3
4
5;; test.asm
db "hello world"
db 0x01,0x02,0x03,0x04,0x05
mov ax,05
mov bx,07
在终端输入 nasm test.asm进行编译,接下来用hex fiend打开生成的二进制文件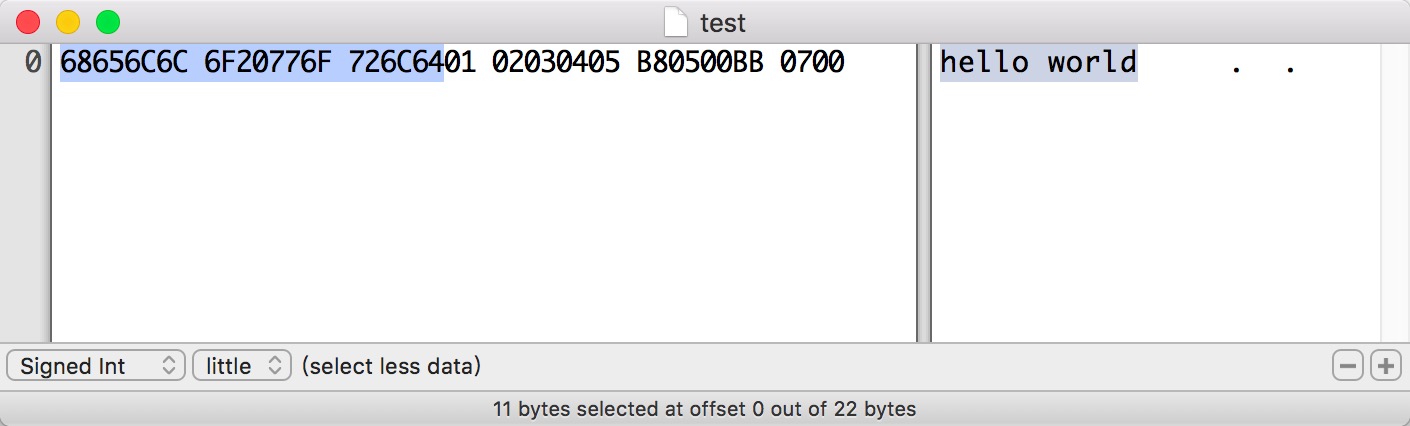
显然 伪指令db将后面的"hello world"转换为ASCII编码后依次写入文件
第二行的伪指令做了类似作用,将0x01,0x02,0x03,0x04,0x05依次写入文件
根据分析,mov ax,05变成了B80500,而mov bx,07则变成了BB0700
可以看出:不管是具有意义的指令,寄存器编号,还是占位的数据,在计算机中都是等价看待的
cpu在执行过程中,不停取指令执行指令的过程中,如果取得的指令没有意义,显然是会发生的,这时候会以中断的形式产生异常,而正常运行过程中,我们只要保证cpu加电后第一条指令是有意义的,那么我们就能够通过人为编程的管理,使得程序中的数据和代码本身实现分离,正确的取解释他们.比如,我们传送一段数据到显存段,那么我们就有理由认为这段数据是表示显示内容的,至于是ASCII还是点阵,取决于我们设置的显卡工作模式.
打印Hello World
很多编程语言的第一个代码都是在控制台上打印Hello World来实现的,汇编语言当然也能实现,当然也能加深你对c语言的认识.比如printf核心干了什么,你还是想弄清楚吧
1 | ;;helloworld.asm |
上面的代码定义了一个数据段,使用系统调用将字符串打印出来,如何使用系统调用呢,就是这个syscall 当然,系统调用需要的”参数”则由寄存器提供,比如字符串长度,字符串地址,系统调用的类型等.其中rdi表示系统调用的编号,系统调用会产生一个中断,陷入内核程序,内核程序根据rdi分别执行不能的功能,所以rdi也叫做系统调用编号.
系统调用编号可参考 linux源码 ,也有网络分享的系统调用表
本例中,分别调用write(系统调用编号1)写入相关数据,然后调用read(系统调用编号0)显示出来
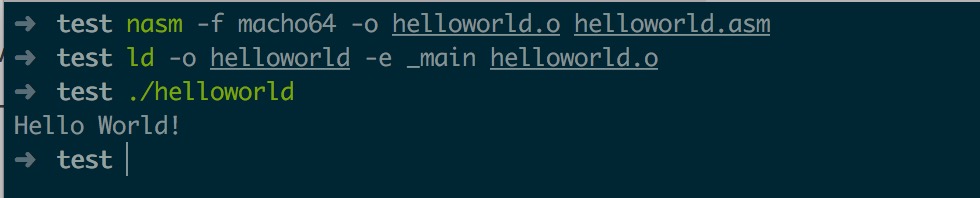
无操作系统的Hello World
显然,上面的代码依赖于系统调用,通过系统调用,内核程序将Hello World写入标准输入流中,标准输入流得到数据后,又通过系统调动进行显示.而这显然无法满足我们对只是的渴望,毕竟内核程序拿到一组ASCII数据后怎么显示在linux呢,其实很简单,无非就是把这些数据搬到显存里,显卡周期性读取显存的数据,显示到显示器上.而怎么写入显存呢,也很简单,显存区域和内存一样,对cpu来说都一样,都是通过地址按照操作内存的方式操作,无非是有一段区域地址里面是显存,一段里面是内存,也许还是一些别的,我们把这个叫做统一编址.
但是,要模拟这个过程却要费些周折,因为我们的代码都是运行在保护模式下的,无法访问全部内存,因此,我们尝试用虚拟机,在没有进入保护模式前显示字符串,这个时候cpu工作在16位下,区域为0xB8000~0xBFFFF.而显卡在文本模式下,每两个字节显示一个字符,可以显示25行,每行80个字符共2000个字符4000个字节.表示字符的第一个字节表示要显示字符的ASCII编码,第二个字节表示一些显示属性,比如前景色背景色,闪烁灯.
计算机启动时,会给cpu加电,并让cpu的cs,ip指向bios的程序,bios程序是写在rom里,通过统一编地,cpu也能像访问内存一样访问rom,唯一的区别是通过一般渠道,无法直接对rom进行更改.而bios程序启动后会检测计算机的硬件状态是否正常,能否工作,然后检查主引导记录(MBR)并加载.
一台电脑有光盘,硬盘,软盘等各种设备存储设备,甚至有多个硬盘,硬盘还有很多分区.里面都有可能有有效的程序,但又不一定都要有.因此bios必须尝试找到其中有效的部分,再装载里面的程序.而是否有效这个标准也是并不是主要的,因此如果一个硬盘是有主引导记录的,那么bios就认为这个主引导记录是合法的,把他加载进去.
一个有效的主引导记录是硬盘开头的512个字节,并且以0x55,0xaa结尾,那么系统就会去加载512字节,并放到内存为0x7c00的位置上,为什么是在这个位置,可能天知道了.
当然现在真正的计算机可能是UEFI BIOS主板,硬盘分区可能是GPT分区,但是这并不影响我们去理解这个过程.具体可以翻阅相关文档或者参考grub2的源码即可.
如下,为一个hello world的源码
1 | ;;helloworld2.asm |
可以看到把es设置为0xb800,以此为段基地址,不停往显存写入数据,最后一个无限循环,后面通过补充0,最后把末尾的两个字节置为0x55和0xaa即可.接下来就是要把程序运行起来了,我们使用visual box,qemu等虚拟机程序执行即可,至于虚拟硬盘文件我们使用固定大小的.vhd即可,因为这个文件的规范比较简单,前面为硬盘的内容,末尾位虚拟硬盘的配置信息.所以我们只需要把我们的程序放到虚拟文件的前部,即可控制虚拟硬盘里的内容.
具体过程如下:
- 首先编译 输入
nasm helloworld2.asm得到helloworld2的二进制文件 - 创建虚拟硬盘文件.如下
 第二步--选择固定大小
第二步--选择固定大小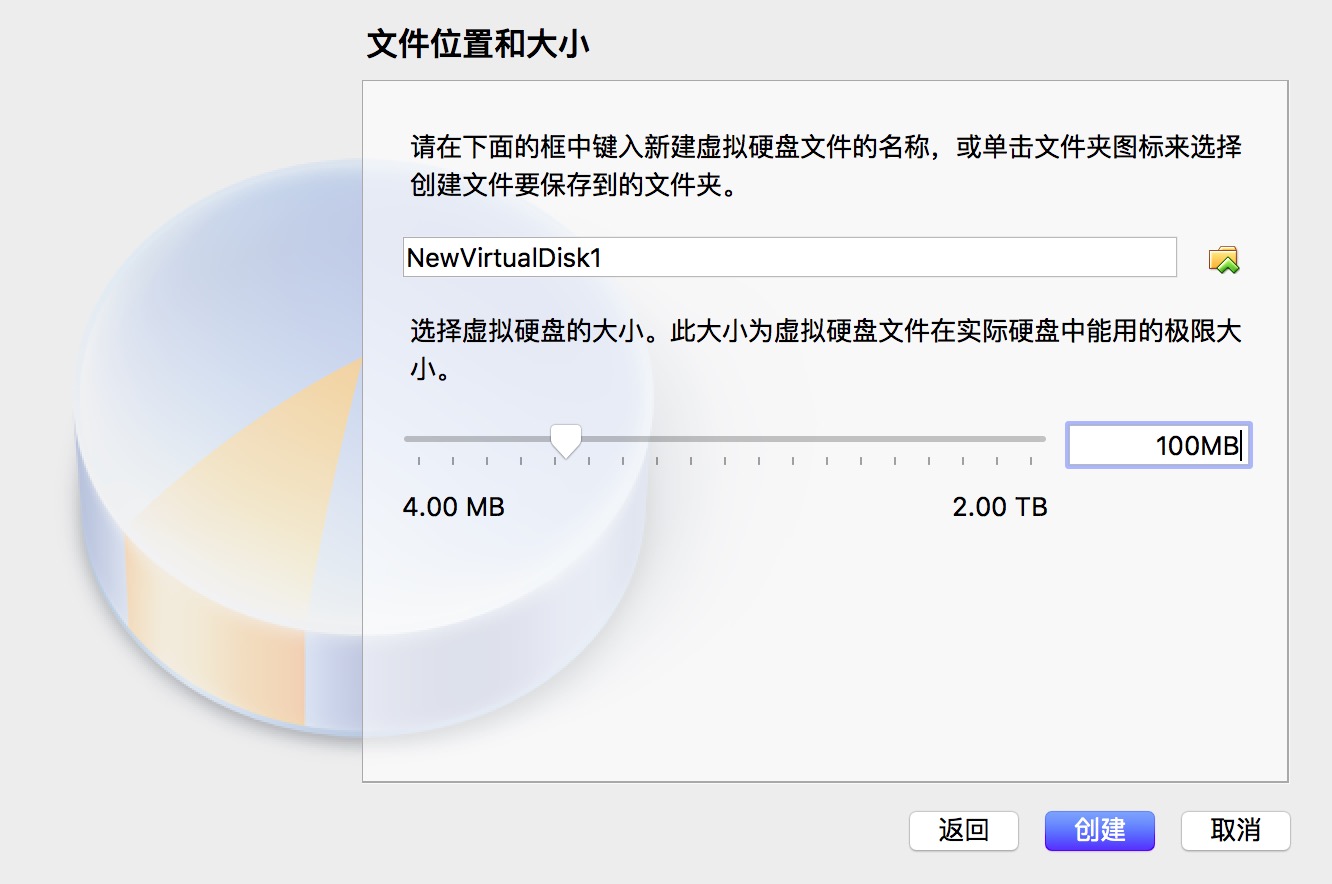 第三部--输入大小
第三部--输入大小 - 将生成的helloworld2写入虚拟硬盘文件的开头部分,这里我分享一个我自己的c++合并的源码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36//merge.cpp
using namespace std;
int main(int argc,char* argv[]) {
if(argc < 2){
cout << "Usage empty.vhd program [target.vhd]";
}
ifstream emptyVHD(argv[0],ios::binary);
ifstream program(argv[1],ios::binary);
ofstream targetVHD(argc>2 ? "target.vhd" : argv[3],ios::binary);
if(emptyVHD.is_open() && program.is_open() && targetVHD.is_open()){
char buf[1024];
while(!program.eof() && !emptyVHD.eof()){
emptyVHD.read(buf, sizeof(buf));
program.read(buf,sizeof(buf));
targetVHD.write(buf,program.gcount());
}
program.close();
while(!emptyVHD.eof()){
emptyVHD.read(buf, sizeof(buf));
targetVHD.write(buf,emptyVHD.gcount());
}
targetVHD.close();
emptyVHD.close();
cout << "copy success" << endl;
}
//error
cout << "open files error";
return 1;
}
使用命令./merge empty.vhd helloworld2 output.vhd合并,接下来使用visualBox或者qemu启动生成的output.vhd即可.
一些改进
可以看到,上面的程序虽然容易理解,但工程性并不好,以下是一个通过批量复制的方式的改进1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20 jmp near start
mytext:
db 'H',0x07,'E',0x07,'L',0x07,'L',0x07,'O',0x07,\
' ',0x07,'W',0x07,'O',0x07,\'R',0x07,'L',0x07,'D',0x07
start:
mov ax,0x7c0
mov ds,ax
mov ax,0xb800
mov es,ax
cld
mov si,mytext
mov di,0
mov cx,(number-start)/2
rep movsw
jmp near $
times 510-($-$$) db 0
db 0x55,0xaa
小结
今天,总结了下计算机的一些本应是基础的知识,却少有被人提及,包括一些本科教材,一上来就是各种寻址,各种模型机,却毫无实际作用,更是难以理解成书的逻辑,尽管现在去看能看懂的大多数,但是介绍一种东西的内在逻辑其实很重要.因此,我会更看重从前起下之间的逻辑连贯.但奈何语言功底较弱,希望多多包涵并指出.本博客集成的评论系统为disqus,自备梯子

